MaskCLR: Attention-Guided Contrastive Learning for Robust Action Representation Learning
Mohamed Abdelfattah
Mariam Hassan
Alexandre Alahi
École Polytechnique Fédérale de Lausanne (EPFL)
firstname.lastname@epfl.ch
Abstract
Current transformer-based skeletal action recognition models tend to focus on a limited set of joints and low-level motion patterns to predict action classes. This results in significant performance degradation under small skeleton perturbations or changing the pose estimator between training and testing. In this work, we introduce MaskCLR, a new Masked Contrastive Learning approach for Robust skeletal action recognition. We propose an Attention-Guided Probabilistic Masking (AGPM) strategy to occlude the most important joints and encourage the model to explore a larger set of discriminative joints. Furthermore, we propose a Multi-Level Contrastive Learning (MLCL) paradigm to enforce the representations of standard and occluded skeletons to be class-discriminative, i.e, more compact within each class and more dispersed across different classes. Our approach helps the model capture the high-level action semantics instead of low-level joint variations, and can be conveniently incorporated into transformer-based models. Without loss of generality, we combine MaskCLR with three transformer backbones: the vanilla transformer, DSTFormer, and STTFormer. Extensive experiments on NTU60, NTU120, and Kinetics400 show that MaskCLR consistently outperforms previous state-of-the-art methods on standard and perturbed skeletons from different pose estimators, showing improved accuracy, generalization, and robustness to skeleton perturbations.
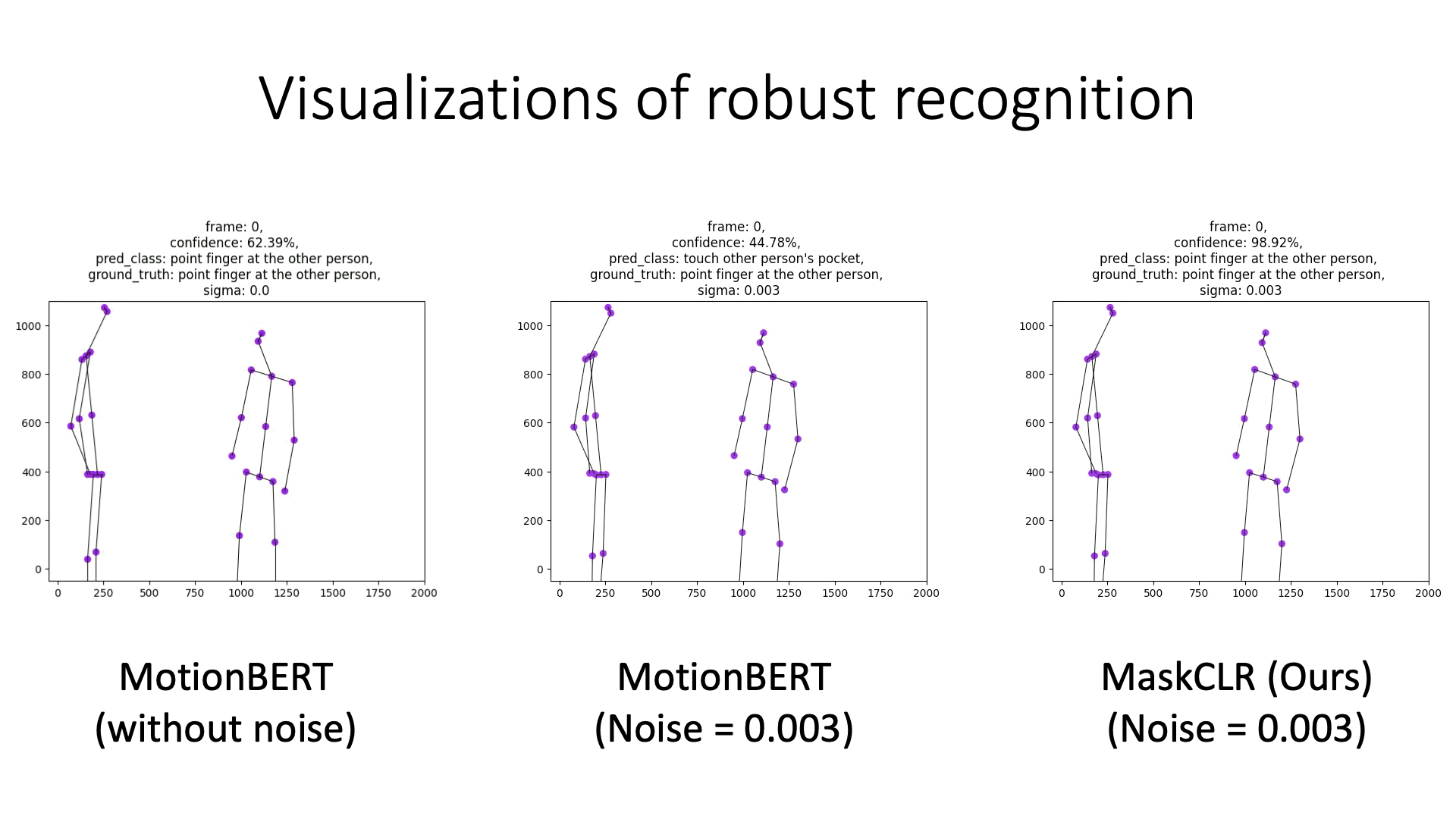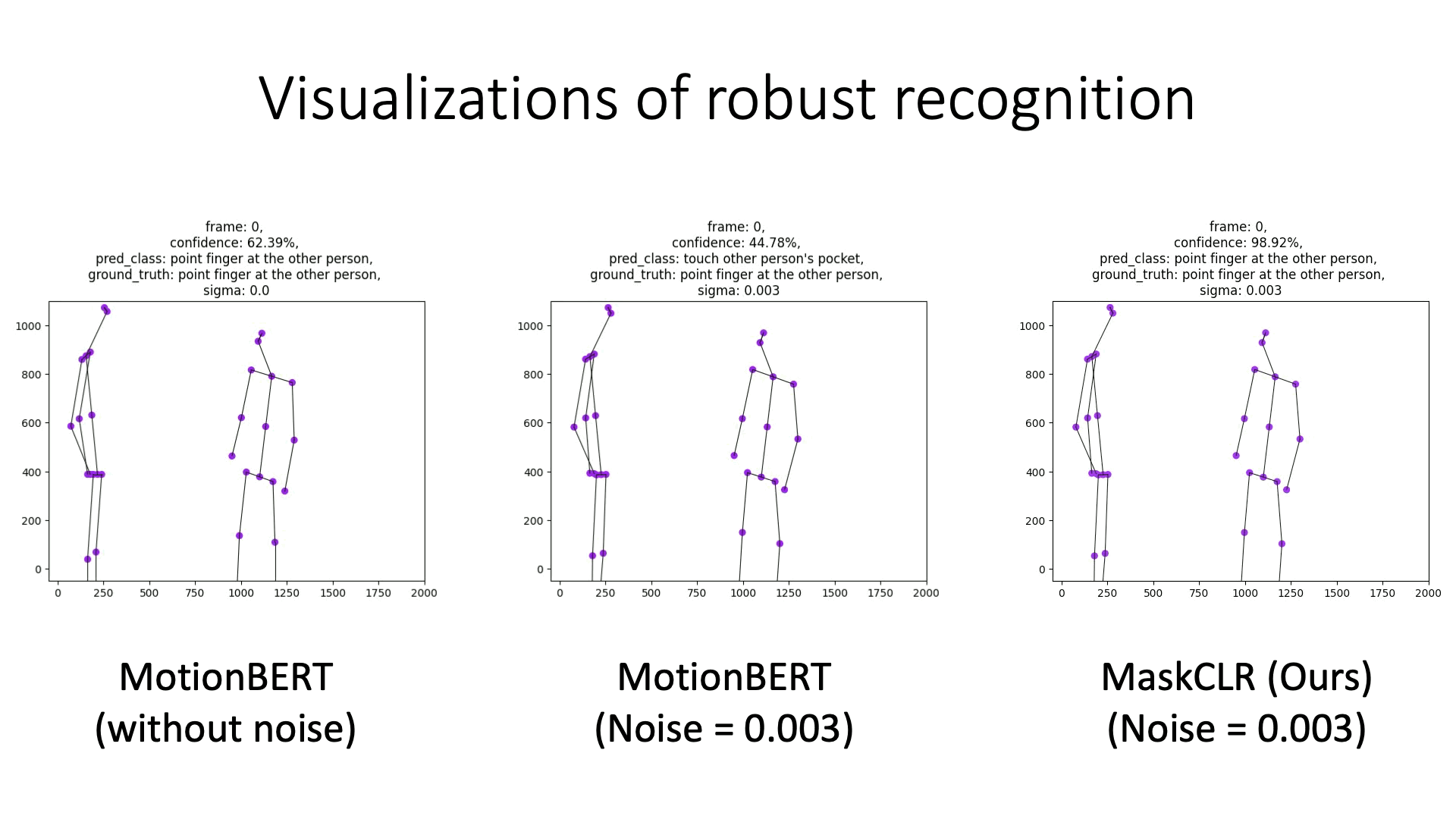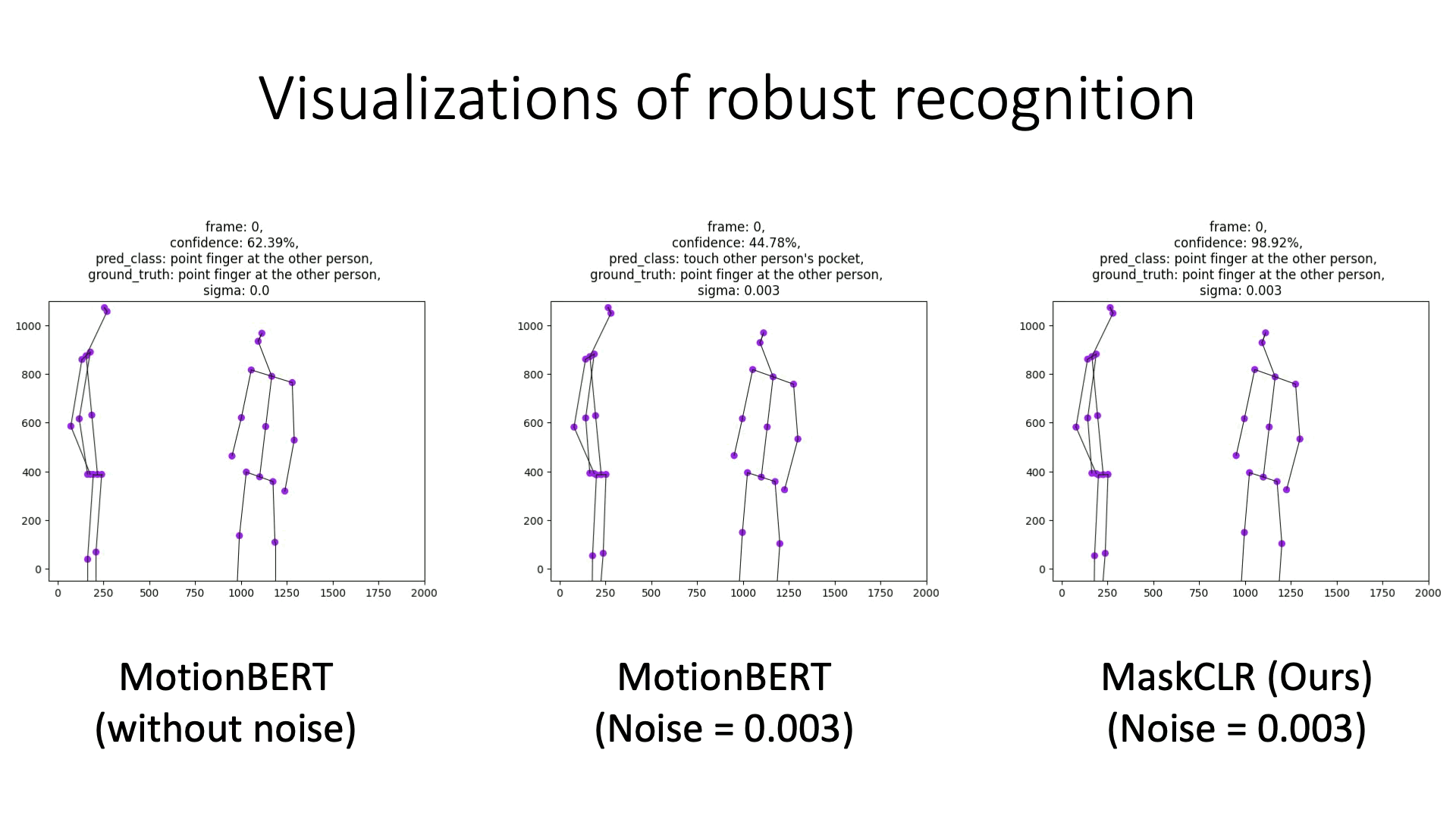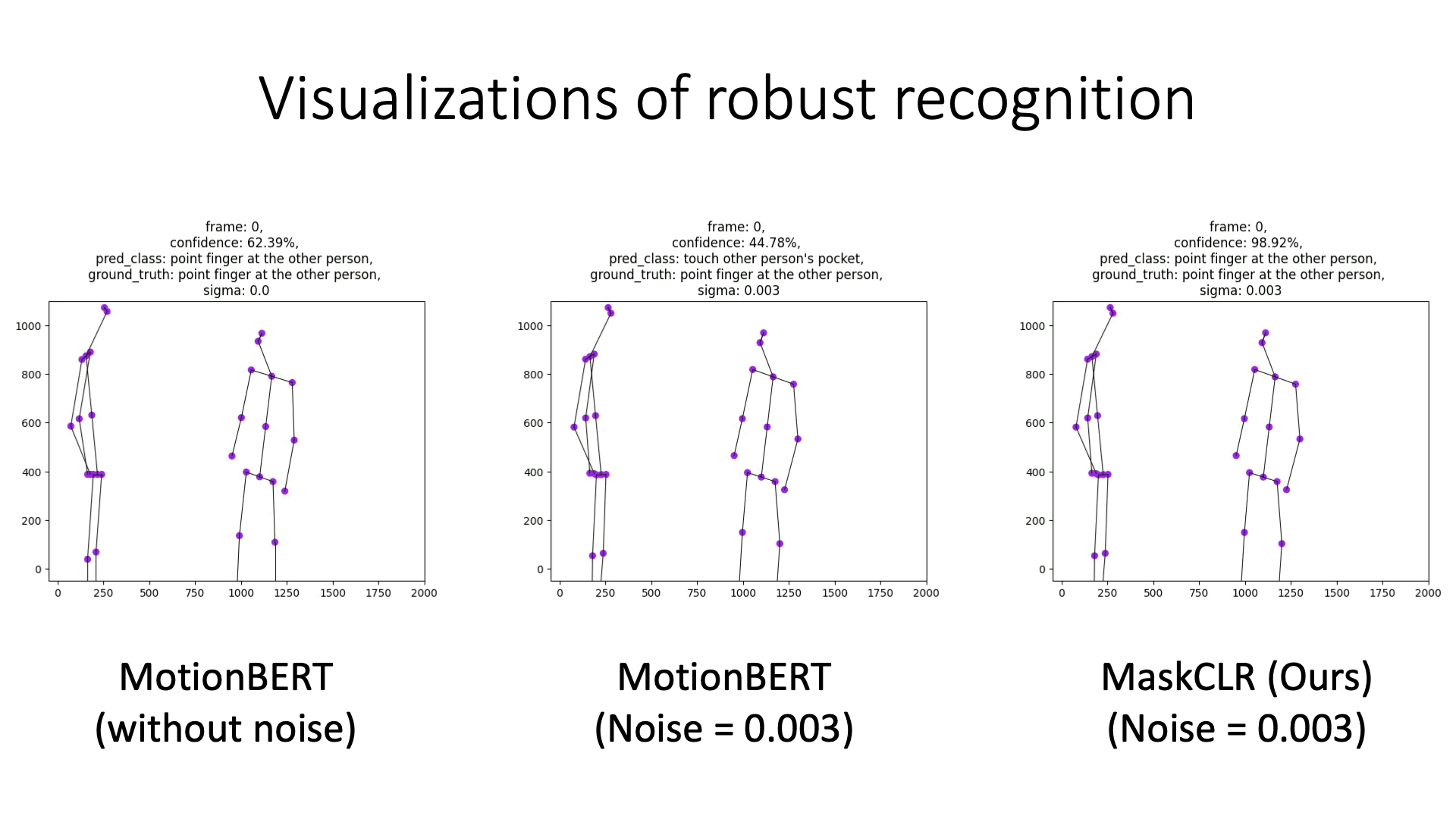
Examples of model predictions under noisy skeletons. MaskCLR is more robust to noise, compared to MotionBERT using the same DSTFormer backbone.
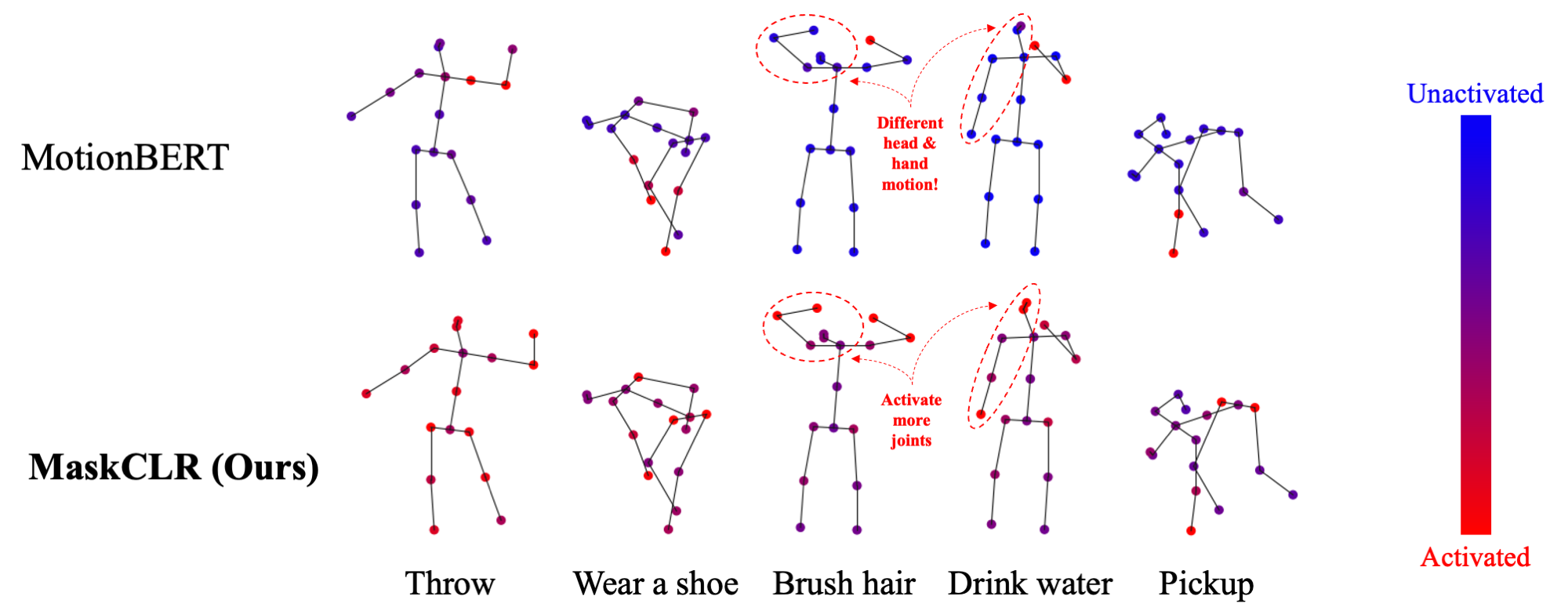
Framework
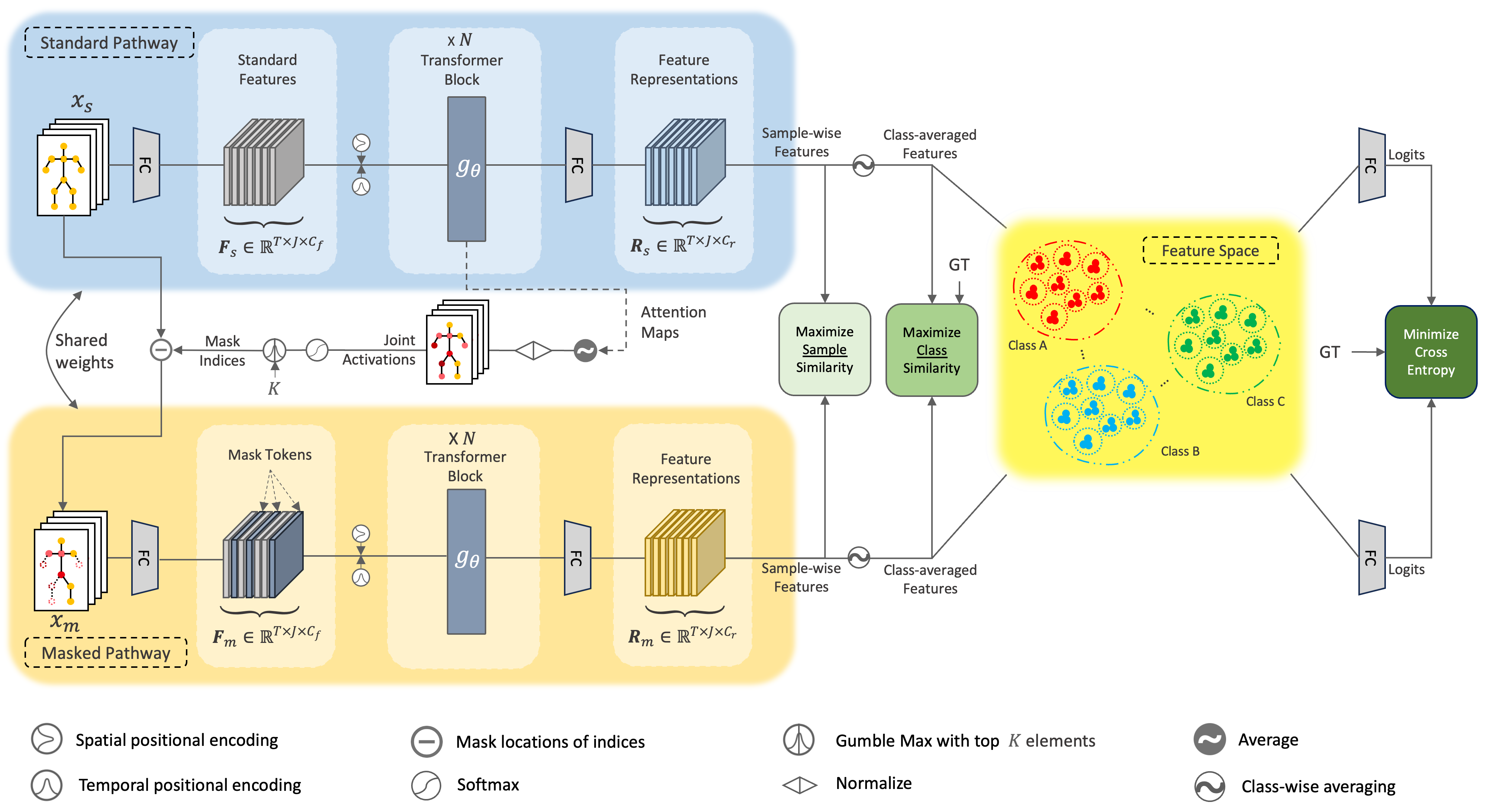
The pipeline of MaskCLR. Our approach consists of two (standard and masked) pathways that share the same weights. The standard pathway takes standard input skeletons while the masked pathway receives mostly the less activated joints from the standard pathway. Initially, the standard pathway is trained alone using the cross-entropy loss. The masked pathway, subsequently, comes into play to encourage the model to explore more discriminative joints. Using sample contrastive loss, we maximize the agreement of feature representations from the two pathways for the same skeleton sequence and vice versa. Additionally, to exploit the high semantic consistency between same-class skeleton sequences, we maximize the similarity between the class-wise average representations from the two pathways using class contrastive loss. Ultimately, the two contrastive losses contribute to the formation of a disentangled feature space, effectively improving the accuracy, robustness, and generalization of the model. At test time, only the standard pathway is used.
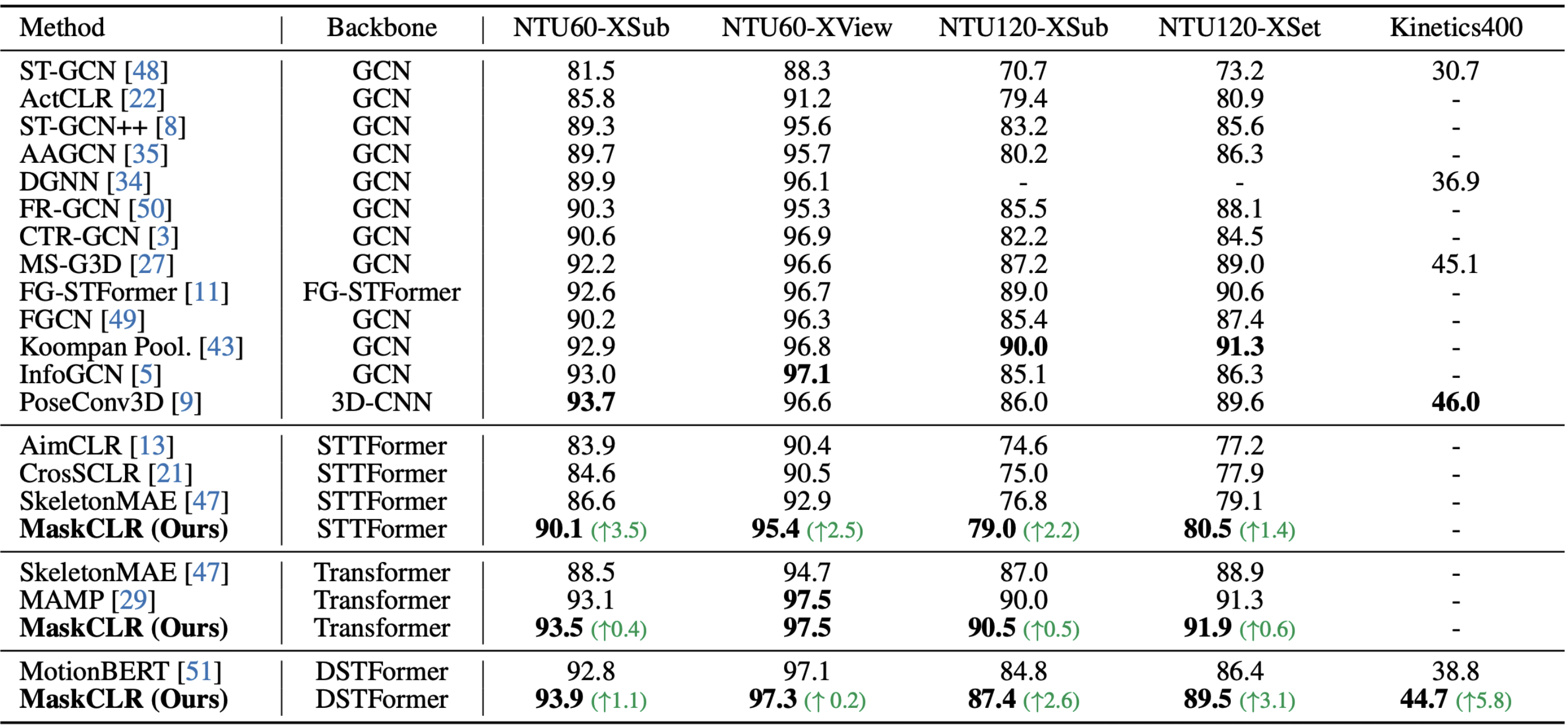
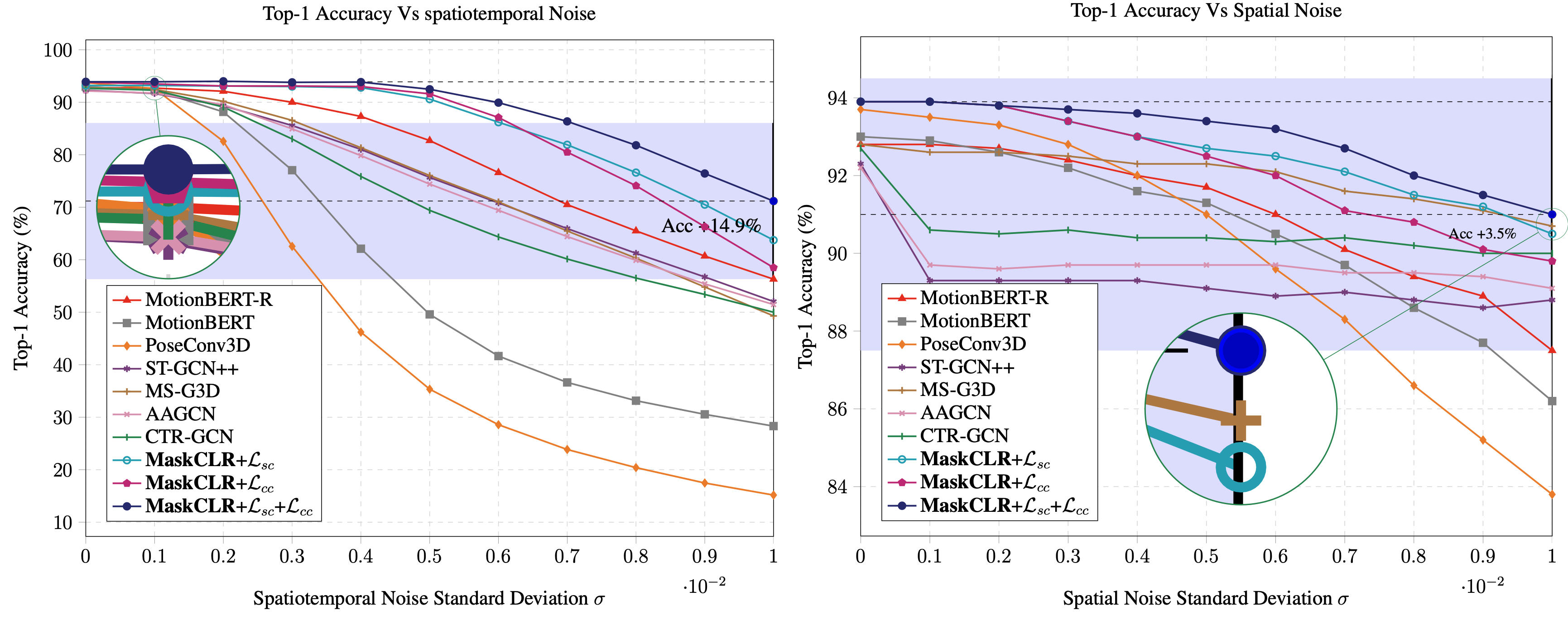
Results

Resources
Reference
[1]. Zhu Wentao, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. "MotionBERT: A Unified Perspective on Learning Human Motion Representations." In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023.
[2]. Duan Haodong, Yue Zhao, Kai Chen, Dahua Lin, and Bo Dai. "Revisiting skeleton-based action recognition." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
[3]. Shahroudy Amir, Jun Liu, Tian-Tsong Ng, and Gang Wang. "Ntu rgb+ d: A large scale dataset for 3d human activity analysis." In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.